1. Introduction
ryptography is the branch of computer science that deals with security. It supports operations such as encryption and decryption. The cryptography is implemented in the form of hash functions, symmetric key algorithms, and public key algorithms. The symmetric and public key algorithms are used for encryption and decryption while hash functions are one way functions as they don't allow the retrieval of processed data. As MD5 and SHA are the two mostly used algorithms in the industry, this paper focuses on secure hash algorithms. MD5 can avoid collision attacks [1] with computational feasibility while SHA -1 attacks also computationally expensive [2]. As SHA-1 is not fully secure, the SHA -2 was introduced [3]. At hardware level in order to improve the performance, GPPs (General Purpose Processors) are used. SHA improvement has been done [10], [11]. This paper introduces the implementation of SHA algorithm at hardware level using techniques described here. They are pipeline techniques [5], [18]; embedded memories used to store constant values [8]; improved addition and balanced delays [4], [12]; unrolling techniques [5], [9], [10], [12]; balanced carry save address and parallel counters [4], [5], [7].
This paper proposes two architectures that can be used with hardware. This is meant for achieving high throughput. The results of implementation of SHA-1and SHA-2 algorithms at hardware level provide more speed when compared with software implementations.
2. II.
3. Hash Functions
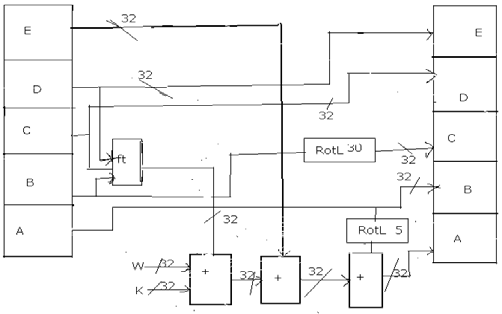
Since from its inception in 1993, the hash algorithms are improved further to have SHA, SHA-1 and SHA-2. The original SHA was revised in 1995 [15] and named as SHA-1 while SHA-2 WAS INTRODUCED IN 2001 which makes use of DM thus making it more robust to security attacks. SHA functions are available with 128, 256 and 512 bits. From the given input message SHA-1 can produce 160 bit message digest as output. Final DM of 256 bits is the output of SHA 256. The computation of SHA 512 is identical to that of SHA 256. The difference is in the size of operands that means it uses 64 bits instead of 32 bits. Moreover the DM of this algorithm has 512 bits the logical function used are also different [15]. Fig. 1 and Fig. 2 show the round calculations of SHA-1 and SHA-2. SHA-1 needs 80 rounds while SHA 256 uses 64 rounds. Each round of SHA-1 requires value from previous round. As rounds are data dependent, it is essential that rounds are carried out sequentially. By unrolling each round computations [10] attempts to speed it up. Another approach increases throughput as it makes use of pipelined structure [11]. As described in [13], high throughput is achieved in SHA-1. Operations rescheduling with respect to this paper has operations rescheduling, hash value initialization, and improved Hash Value Function. The whole computation of SHA-1 is in the A as the rest do not need any computation. The required values are provided by previous round values of various A to D. By adding zero to initialization vector, the internal hash value of first data block can be initialized. Later on this value is loaded into internal registers through multiplexer. In this case instead of the value to the register, it is set to zero as described in [6]. Improving hash value addition is done after all the rounds have been computed for a given data block.
Here the internal variables are to be added to the current DM and it needs four additional adders. Finally SHA-1 data block expansion is described here. 512 bits of each data block is expanded in hardware for efficiency reasons as described in [1]. It can be implemented using XOR operations and also registers. As done in SHA-1, the functional rescheduling can also be applied to SHA-2 as well. However, its computational complexity of it is more. In each round values are calculated as and when required. As described in [19], the part that has to be computed is identified. With respect to operational rescheduling values for B, C, D, F, G and H are obtained directly. However, A and E values can't be computed until they are computed in the previous round. With respect to hash value addition and initialization, similar to SHA-1, the internal variables of SHA-2 also have to be added to the DM. It needs eight adders. For each SHA 256 and SHA 512 of 32 bits and 64 bits respectively an adder is required. The empirical results reveal that DM addition with a shift is more efficient. With respect to SHA-2 data block expansion done by data block expansion unit, it is similar to SHA128 in terms of computations. The XOR operation is replaced by arithmetic addition.
4. III.
5. Implementation
The SHA designs described above has been implemented as processor cores on a Xilinx VIRTEX II Pro FPGA. The FPGA embedded RAMs (BRAMs) are used in order to implement ROM used to store SHA256 and SHA512. Register -based structures can also be used alternatively. One is based on circular fashion in which memory blocks addressed while the other one is based on FIFOs (First -inputs -first -outputs).
6. IV. Performance Analysis and Related Work
The resulting cores have been implemented in different Xilinx devices in order to compare the architectural gains of the proposed SHA structures. SHA -1 core, SHA 256 core and SHA 512 core performance comparisons are provided in tables I, II and III respectively.
7. Design
Lien [11] Lien [11] Our Integration with Processor SHA algorithms that have been implemented are integrated with a processor known as MOLEN polymorphic processor and its operation [14], [16] is based on the coprocessor architectureal paradigm which allows SHA cores to be embedded in a reconfigurable coprocessor with the GPP. This implementation is similar to the one given in [17]. When compared with software implementations, it is capable of achieving throughputs such as 5 Mbit/s and 4 Mbit/s for SHA 256 and SHA 128 respectively and overall speed is increased by 150 times.
8. VI.
9. Conclusion
We have implemented SHA-1 and SHA-2 algorithms at hardware level. This achieves the reutilization and rescheduling of hardware in terms of area and speed. Critical path can be reduced with the help of operation rescheduling. It leads to the very good usage of pipeline structure. The SHA-2 which makes use of DM causes the reduction of reconfigurable resources. This also hides the extra clock cycle delay.
The results of implementation reveals that the hard ware implementation of the hash algorithms are many times better than the software implementations of the same.

| -Exp. | CAST[20] | Helion[21] | Our-Cst. | Our+IV |
| V. |